Harness Engineering
The Definitive Guide to What It Actually Is, Why IT Can't Shut Up About It, and Where Else It Might Actually Be Useful

The Short Version (Summary)
So here’s what happened. In February 2026, OpenAI published a blog post about how they’d built a million-line codebase without anyone actually writing code, and they called the method “harness engineering”. Within weeks the entire tech industry was talking about it like it was the second coming, which is a bit much for what is, fundamentally, the practice of building guardrails, feedback loops, and verification systems around AI agents so they don’t do something catastrophic. The formula is Agent = Model + Harness, and the genuinely interesting finding (confirmed by peer-reviewed research at NeurIPS) is that the harness matters more than the model. Same model, better harness, dramatically better results. That part is real.
What’s also real is that 60% of companies get no material value from AI (BCG, n=1.250), developer trust in AI accuracy has dropped from 40% to 29% even as adoption has risen to 84%, and Gartner reckons 40% of agentic AI projects will be cancelled by 2027.
So we’ve got a discipline that genuinely works when done properly, being adopted by an industry that mostly doesn’t do things properly, described in language that makes it sound more novel than it actually is. Which is, if you think about it, how every useful idea in technology has ever worked.
The harness is real. The hype around the harness is mental. And the cross-industry transfer potential is structurally plausible but historically unlikely to succeed more than about 10–30% of the time, which nobody in the industry seems keen to mention.
Anyway. That’s the short version. The long version has jokes.
Part 1: What Is Harness Engineering, Really?
Look, I’m going to be honest. Harness engineering is not complicated. It’s the practice of building the operational environment around an AI agent. The constraints, the feedback loops, the verification checks, the human approval gates, the logging,,, Everything so that the agent keeps on the track and does useful work instead of confidently generating nonsense and pushing it to production at three in the morning (I know I know… you are already thinking of embedding domain expertise into AI harnessing and wrapping it as a product - I will touch this in following parts). That’s it. That’s what it is.
Birgitta Boeckeler of Thoughtworks, writing on Martin Fowler’s site, gives us the most rigorous framework: she breaks the harness into guides (things that steer the agent before it acts: system prompts, context files, tool definitions, architectural rules) and sensors (things that catch errors after it acts: linting, test suites, type checking, human review). Guides and sensors together create a closed-loop system. Feedforward and feedback. It’s control theory, basically, applied to software agents that are powerful but fundamentally unreliable, which is a description that also fits most of my colleagues over the years, but that’s a different report.
The term was popularised by OpenAI in February 2026, drawing on a metaphor from horse tack (reins, saddle, bit) to describe how you channel a powerful but unpredictable animal toward useful work. Which is a lovely metaphor, right? The AI is the horse. The harness is everything you put on the horse so it doesn’t just run into a wall. And the engineer is the person who designs all that tack and then stands back looking pleased with themselves.
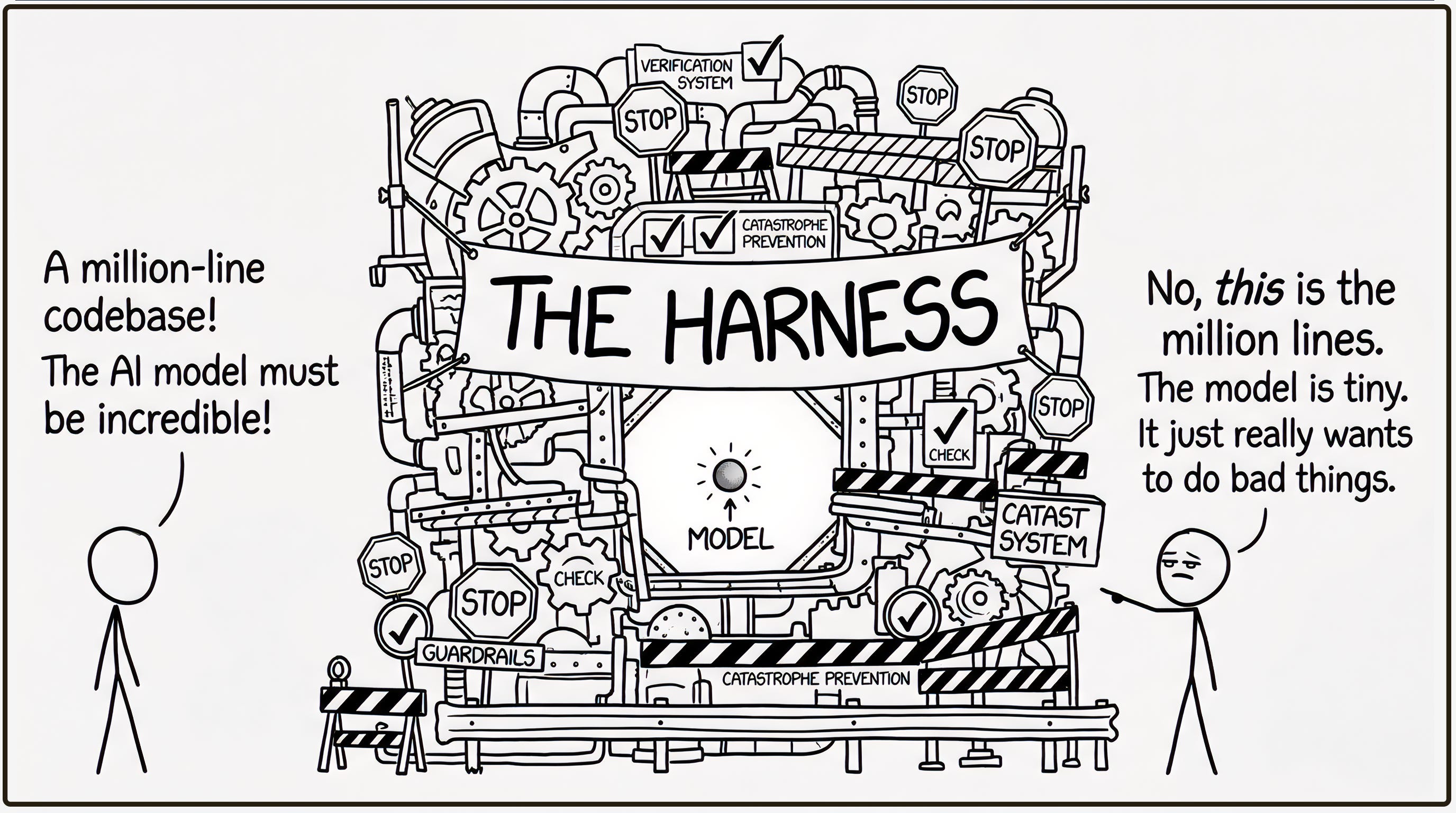
Now,,, here’s the bit that makes the sceptics twitch, and fair enough. The underlying practices are not new. Test harnesses have existed since 1979, when Glenford Myers published The Art of Software Testing. CI/CD pipelines have been gating deployments for decades. Linting, type checking, sandboxing, approval workflows,,, all of this is established software engineering. Chayenne Zhao captured the sceptical position rather neatly on X: “Do these people have any ideas beyond coining new terms for old ones?”
And she’s got a point. Sort of. The practices are old. But the composition (applying these practices specifically to autonomous AI agents, where non-determinism makes verification structurally necessary rather than merely prudent) that’s the new bit. Whether this justifies a whole new discipline name or is just good engineering applied to a new domain is, honestly, contested terrain. The evidence supports both readings, and anyone who tells you they’re absolutely certain which one it is hasn’t thought about it carefully enough, or they’re selling something. Probably both.
The evolution looks something like this: prompt engineering (2022–2024) was about what you say to the model. Context engineering (2025, Andrej Karpathy’s term) expanded that to what context you give the model. Harness engineering (2026) goes further. It’s about what environment you build around the model. Each step subsumes the last. Whether this represents a genuine intellectual progression or a series of rebrandings is, I think, a question that future historians will find hilarious regardless of the answer.
The important disambiguation, because this trips everyone up: “harness engineering” in 2026 means the AI agent discipline described above. Harness.io is a separate $5.5B CI/CD platform that happens to share the name. And physical wiring harnesses (the $67.4B automotive market) are actual cables in actual cars. Three different things. One word. Welcome to technology, where naming things is apparently harder than building them.
Part 2: How It’s Actually Changing IT
The Stuff That’s Real
If there’s anything in this report you should actually believe, it’s this.
1. The harness matters more than the model. This is the headline finding, and it’s robust.
Yang et al.’s NeurIPS 2024 paper (published at the field’s highest-prestige venue, which is not nothing) demonstrated 3–5x improvements in agent task completion from scaffolding changes alone. A 2026 preprint corroborated this with 10–15 point performance variations across 40+ agents from scaffold design differences. And LangChain showed a jump from 52.8% to 66.5% on Terminal Bench 2.0 by changing only the harness, not the model.
Now, the LangChain result is self-reported and uses their best configuration rather than their average, which could be flagged as cherry-picking. Fair enough. But the NeurIPS paper is peer-reviewed and independent. Same horse, better tack, better race. That part is real.
2. The AI Velocity Paradox is real, and it’s a genuine problem.
Organisations are writing code faster and shipping it worse. Three independent methodologies converge on this: DORA found a correlation between AI adoption and declining delivery stability (-7.2%, though this is correlational, not causal, and the metric definitions changed between years, which everyone seems to forget). Harness’s own survey found 45% of deployments involving AI-generated code lead to problems and 72% of organisations have experienced at least one production incident from AI-generated code. GitClear found 41% higher code churn in AI-assisted repositories.
So we’ve got a situation where the coding got faster but the software didn’t get better. Which is like having a faster printer that only prints typos. The velocity paradox is the strongest argument for harness engineering: if you’re going to generate code at ten times the speed, you need verification infrastructure that can keep up. Otherwise you’re just making a mess more efficiently, which, come on, we were already good at that.
3. Stripe’s AI agent system is the best-evidenced enterprise case study.
Stripe’s “Minions” system merges 1.000 - 1.300+ pull requests per week using internal AI agents. Every PR gets a human review before merging. This is documented across Stripe’s own dev blog, InfoQ, ByteByteGo, and Awesome Agents… multiple independent sources confirming the same claim. It is real, it is specific, and it includes the crucial caveat that humans still review everything. That last bit is the part most people skip when they cite the number, which tells you something about how the industry processes evidence.
4. Developer trust in AI accuracy is falling as adoption rises.
Stack Overflow’s 2025 Developer Survey (and this is one of the largest and most-cited surveys in the field) found trust in AI code accuracy dropped from 40% to 29% in one year while adoption rose to 84%. Sonar’s 2026 survey corroborated this: 96% of developers don’t fully trust AI-generated code. JetBrains found quality is the top concern, outranking job security.
So developers are using AI more and trusting it less. Which sounds paradoxical but is actually very sensible, right? It’s like knowing that your car’s sat-nav is sometimes wrong but using it anyway because you can’t be bothered to read a map. The trust deficit is not irrational - it’s empirical. Developers have seen the output. They know. And this trust gap is, quietly, one of the strongest arguments for investing in verification infrastructure. If the people using the tools don’t trust the output, maybe the output needs more checking. Just a thought.
5. AI-generated code has a structurally different security vulnerability profile.
This one’s peer-reviewed across multiple independent studies (ACM TOSEM) found 29.5% of Python AI-generated snippets had security weaknesses. CSET Georgetown found XSS failures in 86% of relevant generated code. USENIX Security 2025 published on “slopsquatting” (package hallucination) as a novel attack vector where AI recommends packages that don’t exist, which attackers then register. That’s genuinely new and genuinely alarming.
6. Only 5% of companies are generating AI value at scale.
BCG’s September 2025 study found that only 5% of companies (they call them “future-built”) are achieving value at scale from AI. This is consistent with Gartner’s 40% cancellation prediction and McKinsey’s earlier adoption research. The 5% requires high digital maturity, stable leadership, and advanced technological and governance architecture, which is something that most businesses do not have and never will. So when someone tells you harness engineering will transform your organisation, the honest answer is: maybe, if you’re in the 5%. For the other 95%, it’ll be one more thing you bought a subscription for and never properly implemented. Like the gym membership.
The Stuff That’s Mostly Real
The METR productivity study - it’s complicated, and anyone citing “19% slower” without the update is being a bit naughty.
METR’s original RCT found experienced developers were 19% slower with AI tools, with a 39-point gap between perceived and actual productivity. This became the most-cited study in the industry overnight. The problem is that METR themselves published a February 2026 update substantially weakening the finding: their follow-up with newer tools narrowed the effect to approximately -4% (95% CI: -15% to +9%), which is not statistically significant. METR explicitly stated their new data gave “an unreliable signal of the current productivity effect of AI tools”. The 39-point perception gap (developers thought they were faster when they weren’t) is actually more robust than either absolute figure, and it’s the more interesting finding anyway.
Harvey’s legal AI results are promising but it’s one company.
Harvey, the $11B legal AI startup, demonstrated that harness engineering improved average task scores from 40.8% to 87.7% across 12 legal tasks. That’s dramatic. But it’s Harvey’s own internal benchmark, on 12 tasks, vendor-reported, with no published methodology or independent replication. And it is a single company. n=1 is not a pattern.
The Stuff That’s Probably Bollocks
And here’s the bit I was looking forward to. Every hype cycle produces claims that survive on vibes rather than evidence, and harness engineering is no exception. Sort of the whole point, really.
The Rakuten “99.9% accuracy” claim is genuinely misleading.
You’ll see this cited everywhere (although the blog post is not available anymore on their website, you can still find it on the internet, and people are still citing it). “Rakuten ran a 7-hour autonomous coding session on a 12.5-million-line codebase achieving 99.9% accuracy” Sounds brilliant, doesn’t it? Makes you think AI can write enterprise code with near-perfect reliability. Except that “99.9% accuracy” refers to numerical accuracy of an activation vector extraction method compared to a reference implementation. One algorithm. One well-scoped task. The way it’s cited - next to Stripe and OpenAI, adjacent to productivity claims - implies general-purpose enterprise reliability. That’s not what the evidence shows. It’s like saying someone scored 99.9% on a spelling test and then claiming they’re 99.9% literate. I mean... come on.
SWE-bench Verified is dead. Stop citing it.
Here’s a fun one. OpenAI’s own Frontier Evals team abandoned SWE-bench Verified in February 2026 after auditing it and finding that 59.4% of failed test cases were themselves flawed. Every frontier model tested could reproduce verbatim gold patches for certain tasks, which means the benchmark was contaminated. Models scoring 80% on Verified scored about 23% on the replacement SWE-bench Pro. So when you see “71.7% accuracy” cited as evidence of frontier coding capability (and the Stanford AI Index cited exactly that) what you’re actually seeing is a score on a test the test-maker no longer trusts.
The “10x productivity” claims are survivorship bias in a trench coat.
Various conference presentations and blog posts claim “~10x productivity” gains from harness-engineered environments. These numbers come from OpenAI’s internal Codex team and similar frontier organisations. The median enterprise experience, based on IDC’s survey and DORA data, is closer to a 10–35% improvement with significant downstream costs. Citing what Stripe or OpenAI achieve as representative is like citing what Usain Bolt achieves as evidence that everyone should run the 100 metres in under 10 seconds. He can. You can’t. Sorry.
“85% of ML models never reach production” is a zombie statistic.
This has been circulating since about 2019, attributed to various sources, with no rigorous peer-reviewed study establishing the figure. It’s widely cited in MLOps marketing materials because it’s useful, not because it’s verified. For what it’s worth, even if it’s true, 85% is not uniquely terrible. 70% of digital transformations fail. 90% of startups fail. Sometimes things just don’t work out.
Part 3: Cross-Industry Transfer - Where Else Could This Actually Work?
Before we get into the specific opportunities, I need to say something that nobody in the industry seems keen to acknowledge. The base rate of successful cross-industry technology transfer is, depending on which research you read, somewhere between 10% and 30%. Digital transformation fails 70% of the time (Bain, 2024). BCG says only 5% of companies achieve AI value at scale. These are not encouraging numbers. Every transfer opportunity below is structurally plausible, and some of them are genuinely exciting, but history says most of them will not work. Not because the ideas are bad, but because most things don’t work. That’s the honest starting position.
The Top 3 Opportunities (With Actual Evidence)
1. Construction & Real Estate - The $1.6 Trillion Coordination Problem
This one genuinely surprised me. Construction is the least digitised major industry in the global economy (McKinsey), with productivity growth averaging 1% annually over the past two decades while manufacturing hit 3.6%. Projects routinely overrun budgets by 80% and schedules by 20 months. The structural waste is estimated at $1.6 trillion per year globally, and the primary cause is coordination failure: dozens of trades, hundreds of document types, thousands of regulatory requirements, and nobody talking to each other properly.
The structural mapping to harness engineering is surprisingly deep. BIM (Building Information Modeling) is literally declarative specification: you declare what the building should be, like a CLAUDE.md file for a structure. Building inspection is staged verification against acceptance criteria. Change orders are pull requests. Clash detection is automated linting. 4D scheduling is CI/CD orchestration for physical construction. And the “rollback” mechanism is demolition, which costs slightly more than git revert.
Nobody is building the AI orchestration layer that connects BIM design intent to physical execution with real-time verification and regulatory compliance. Procore is a document management system, not a harness. The whitespace is enormous. The market entry point is automated building code compliance checking… currently done manually by plan reviewers, taking weeks, prone to error, and boring enough that AI might actually be the right solution.
The catch, and it’s a real one, is that construction is extremely fragmented. Thousands of small subcontractors per project, each with different technology maturity. Some of them are still using paper and WhatsApp. Getting them all onto a unified orchestration platform is a different kind of hard than getting developers onto GitHub. But if even a 1% reduction in global construction waste is achievable, that’s $16B in annual value creation. Which is not nothing, right?
2. Agriculture & AgTech - The Missing Decision Layer
Agriculture has excellent sensors. Satellite imagery, soil moisture monitors, weather stations, drone surveys,,, It has improving actuators. John Deere’s autonomous tractors, variable-rate fertiliser applicators,,, What it doesn’t have is the bit in the middle. The orchestration layer that connects “here’s what the field looks like” to “here’s what you should do about it” with appropriate verification and decision gates barely exists at scale. The structural gap is identical to pre-harness IT: powerful components, poor integration, manual decision bottlenecks.
The food system represents $8-10 trillion in annual global value, and precision agriculture promises 10–20% yield improvements, but only if someone builds the decision harness. An “agricultural harness” would fuse multi-source data into a unified field state, generate intervention recommendations within agronomic and regulatory constraints, execute low-risk decisions autonomously (irrigation timing), and route high-cost decisions (chemical applications, harvest timing) to farmer approval. That’s guides, sensors, human-in-the-loop gates, and observability. It’s harness engineering with dirt on its boots.
The market entry point is irrigation scheduling for specialty crops (high value per acre, water-sensitive, data-rich, clear feedback signals, immediate ROI). The crop simulation community (DSSAT, APSIM) has decades of experience with simulation harnesses for agricultural systems that the AI agent verification world could learn from.
Why nobody has done it? AgTech has attracted $5B+ in annual venture investment, but most of it went to individual sensing or actuation products rather than the orchestration layer. The venture model favours hardware and SaaS point solutions over the harder systems-integration play. Which means the biggest opportunity is the boring one. Naturally.
3. Compliance-as-a-Harness - Beyond BigLaw Into the Regulatory Everything
Harvey proved that harness engineering works in legal, but Harvey targets AmLaw 100 firms - the Stripes of the legal world. The much larger market is enterprise compliance: internal compliance departments, corporate legal teams, government regulatory agencies, and mid-market companies that face the same structural problems but can’t afford Harvey-tier solutions. The global RegTech market is $20B+ growing at 16.6%+ CAGR.
Here’s the insight that makes this a genuine transfer opportunity rather than just “do what Harvey did but worse”: every regulated industry has compliance workflows that are structurally identical to CI/CD pipelines. Regulatory change detection → impact assessment → policy update → implementation → verification → audit documentation. That’s a pipeline. The domain-specific content changes between healthcare (HIPAA), finance (SOX, Basel III), manufacturing (ISO quality), energy (NERC CIP), and construction (building codes), but the structural pattern is the same. Only the context files differ.
Funny thing is that some parts of this were actually part of my PhD work::: a “compliance harness platform” would monitor regulatory changes, assess impact using domain-specific context, generate draft policy updates with citations, route them through approval workflows with human review gates, track implementation, and generate audit documentation with provenance trails. This is Harvey’s autoresearch pattern applied to compliance rather than litigation, with the critical addition that it works across industries.
The market entry point could be automated regulatory change monitoring and impact assessment for financial services compliance departments. Currently done by junior analysts reading Federal Register notices. Bounded, high-frequency, clear value. The kind of work that’s important, tedious, and error-prone - which is basically the ideal job description for a well-harnessed AI agent.
Part 4: So What Should You Actually Do?
If You’re an IT Leader or CTO
Stop buying models and start investing in the environment around them. The evidence is clear that harness quality outperforms model shopping for most enterprise use cases. Specifically:
Buy commodity orchestration, build domain-specific constraints. AgentKit, LangChain, and similar frameworks handle the plumbing. Your competitive advantage is in encoding your workflows, your approval logic, your domain knowledge into the harness. That’s the bit vendors can’t do for you.
Start with one bounded, high-frequency workflow. Stripe didn’t start by harnessing everything. They started with one-shot coding agents for specific migration tasks. Pick your equivalent: the most repetitive, best-defined, most frequently executed task in your engineering org. Build the harness there. Learn. Expand.
Accept supervised autonomy, reject fantasy autonomy. Anthropic reports developers can fully delegate only 0–20% of tasks. Harvey bakes in human checkpoints. OpenAI still emphasises control systems and review. If your plan involves “lights-out engineering”, you don’t have a plan. You have a wish.
Put platform engineering in charge of the harness. This is not a developer-by-developer decision. It’s a shared abstraction that belongs on the platform team, just like CI/CD and observability.
If You’re a Business Executive
The ROI is real but conditional. BCG says 5% of companies achieve AI value at scale. The 5% have mature engineering infrastructure, stable leadership, and high digital and AI governance maturity. If you don’t have those prerequisites, harness engineering won’t save you. It will be one more thing your organisation fails to implement properly.
Budget for the harness, not just the model. Anthropic’s own experiment showed a simple un-harnessed approach cost $9 and produced broken code, versus a structured iterative harness costing $200 but producing functional code. The model subscription is the cheap bit. The verification infrastructure is where the real investment goes.
Expect the velocity paradox. Your developers will write code faster. Your defect rate may increase. Your deployment failures may spike. This is not the AI failing. This is your downstream governance failing to keep pace. Budget accordingly.
If You’re an Investor
The harness layer is where enterprise value accrues, but it’s not where market valuations currently sit.Cursor at $29.3B and Harvey at $11B represent different theses - Cursor bets on model-integrated tooling, Harvey bets on domain-specific harness engineering. The harness thesis has better academic evidence. The model thesis has better market momentum. Pick your timeframe.
Cross-industry transfer is high-upside, high-risk. Construction and agriculture have enormous addressable markets and near-zero competitive whitespace for harness-style orchestration. But the base rate of cross-industry technology transfer is 10–30%. Price that in.
Watch for compliance-as-a-harness. The RegTech market ($20B+, 16.6%+ CAGR) is structurally identical to what Harvey built for BigLaw, but for every regulated industry. The platform that cracks multi-industry compliance orchestration owns a very large and very boring market, which is exactly the sort of market that produces durable returns.
If You’re in an Adjacent Industry
Check whether your domain has the seven structural principles. Abstraction behind interfaces, declarative specification, multi-step orchestration, closed-loop feedback, human-in-the-loop gates, composable modules, and observability. If your industry’s workflows map to these principles (and most regulated, multi-step, error-costly workflows do) then harness engineering principles apply. The question is whether the economics justify the investment, not whether the analogy holds.
Import the verification patterns, not the vocabulary. You don’t need to call it “harness engineering”. You need staged verification gates, graduated autonomy, human review at materiality thresholds, and audit trails. Call it whatever you want. Call it Dave. I don’t care. The patterns work regardless of what you name them.
Acknowledge the reversibility gap. In software, you can roll back a deployment. In construction, you cannot un-pour concrete. In agriculture, you cannot un-plant a field. In medicine, you cannot un-administer a drug. This means the harness value in physical industries concentrates on prevention (guides, constraints, simulation) rather than correction (rollback, recovery). That’s not a minor adaptation. It changes the reliability threshold and the cost structure fundamentally.